
 お悩み女子
お悩み女子非効率なデータ収集から早く解放されたい
 なべくん
なべくんPythonを使ってウェブクレイピングすれば、爆速でデータ収集できますよ。
スクレイピングは、以下表の通りにさまざまなプログラミング言語でウェブサイトの情報を収集できますが、本記事では特に取り扱いが柔軟なPythonでのウェブスクレイピング方法について解説していきます。
| 項目 | Python | PHP | Java Script |
|---|---|---|---|
| 書きやすさ | |||
| ライブラリ数 | |||
| 情報量 |
Pythonウェブスクレイピングを使えば、これまで何日もかかっていたデータ収集作業や何度も何度も繰り返しチェックしていた作業が数分~数時間で完了し、爆速でデータ収集を効率化できます。
ただし、ウェブスクレイピングは相手先のサーバーに負荷をかける行為であるため、サイトによっては利用規約でスクレイピングを明確に禁止している場合があります。
- Pythonで効率的にウェブデータを収集する具体的な手法とライブラリ
- ウェブスクレイピングにおける法的・倫理的なリスク回避と注意点
- Pythonで実際にスクレイピングするテストコード
本記事は、スクレイピングを推奨・助長する目的で執筆しておりませんが、教育目的としてデータ収集を安全かつ安定的に効率化するためにも、ぜひ本記事を参考にしてください。
スクレイピングにおけるPythonとそれ以外の言語の違い
 お困り女子
お困り女子スクレイピングってPythonだけじゃないの?
なべくんPHPやJava Script、GASなどさまざまな言語でスクレイピングができますよ。
スクレイピングと一口に言ってもユーザーであるあなた自身の作業環境によって、以下の通りにさまざまなプログラミング言語でスクレイピングが可能です。
- Java Script
- PHP
- Python
- GAS(Google App Script)
- C#
上記以外にもExcel VBAやGo言語などさまざまな言語でスクレイピングが可能。
特にPythonがスクレイピングとして選ばれる理由はおもに以下の3つ。
- 言語自体が比較的書きやすい
- ライブラリーが豊富
- 参照情報が豊富
それぞれの内容について見ていきましょう。
Pythonは他言語よりもコード自体が書きやすい
Pythonがスクレイピングする際に用いられる理由の一つとして、言語自体が書きやすいことが挙げられます。
以下に各言語のサンプルコードを記載いたします。
# 必要なライブラリをインポート
import requests
from bs4 import BeautifulSoup
# 対象のURL
url = 'http://books.toscrape.com/'
try:
# URLにアクセスしてHTMLデータを取得
response = requests.get(url)
# 文字化けを防ぐために文字コードを正しく設定
response.encoding = response.apparent_encoding
# BeautifulSoupを使ってHTMLを解析
soup = BeautifulSoup(response.text, 'html.parser')
# titleタグを見つけて、その中のテキストを取得
title = soup.find('title').text
# 結果を出力
print("取得したタイトル:")
print(title)
except requests.exceptions.RequestException as e:
print(f"エラーが発生しました: {e}")プログラミング言語に抵抗がない人を除いては、何が書いてあるのかよく分かりませんね(笑)
とはいえ、同じスクレイピング処理をそれぞれの言語でコードを書くとPythonが少ないコード量で済み、一般的にわかりやすいとされています。
前述したサンプルコードはとても簡潔かつ基本的なコードですが、本番環境のより本格的な内容のスクレイピングを実装しようとするとコード行が300行以上になることも珍しくなく、書くコードが少ない分、エラーやミスが少なく安定した挙動が期待できます。
余談になりますが、スクレイピングしてきたデータをそのままにすることは少なく、何らかのデータ加工や集計などの後工程が発生するため、データ加工や集計などのライブラリが豊富にあるPythonは使い勝手が良く、多くの人に選ばれています。
Pythonはスクレイピングのライブラリーが豊富
Pythonがスクレイピングする際に用いられる理由の一つとして、スクレイピングのライブラリーが豊富なことが挙げられます。
| ライブラリ | 主な特徴 | メリット | デメリット | 活用シーン |
|---|---|---|---|---|
| Requests | HTTPリクエストライブラリ | シンプル、軽量、高速 | 動的サイト不可、解析機能なし | 静的サイトのHTML取得 |
| Beautiful Soup | HTML/XMLパーサー | 柔軟なHTML解析、学習容易 | 単体で通信不可 | HTMLからのデータ抽出 |
| Scrapy | スクレイピングフレームワーク | 大規模、高速、多機能、非同期 | 学習コストが高い | 大量ページの効率的な巡回 |
| Selenium | ブラウザ自動化(古参) | 動的サイト対応、情報豊富、複数ブラウザ対応 | 低速、環境構築が煩雑なことも | ログイン、複雑な操作が必要なサイト |
| Playwright | モダンなブラウザ自動化 | 高速・安定、動的サイトに強い、公式サポート、高機能 | Seleniumよりは情報量が少ない | 動的サイト全般、現在の第一選択肢 |
| Puppeteer (pyppeteer) | ブラウザ自動化(JSが本家) | (JS版は)高機能、動的サイトに強い | (Python版は)開発停滞、非公式ポート | 参考:現在はPlaywrightを推奨 |
上記の表の通り、Pythonにはスクレイピングを行うためのライブラリーが多数存在し、以下のようにスクレイピングの目的や対象サイト・用途などに応じてライブラリーを組み合わせて使用することがほとんどです。
- コンテンツ取得・解析系(静的サイト向け)
- Requests: WebページにアクセスしてHTMLファイルなどをダウンロードする担当。
- Beautiful Soup: ダウンロードしたHTMLの中から、目的の情報を抜き出す担当。
- ※この2つはセットで使われることが非常に多いです。
- ブラウザ自動化系(動的サイト向け)
- Selenium: 実際にブラウザを起動・操作して、人間が見るのと同じ画面を表示させてから情報を取得する。
- Playwright: Seleniumと同様にブラウザを自動操作する、よりモダンで高機能なライブラリ。
- フレームワーク系(大規模クローリング向け)
- Scrapy: データ収集の「リクエスト→ダウンロード→解析→保存」という一連の流れを効率的に管理するための骨組み(フレームワーク)。
Pythonは他の言語と比較して参考情報が豊富
Pythonがスクレイピングする際に用いられる理由の一つとして、参考情報が豊富なことが挙げられます。
上記のプログラマー御用達サイト以外にもさまざまな人が情報発信しているので、Pythonでスクレイピングする際の情報源として、まず困ることがありません。他言語の場合、そもそも情報が少ないまたはない場合がほとんど。
とはいえ、情報が古いものもあるため、実際にコーディングをする際にはライブラリーのバージョンや仕様に注意が必要です。
続いては、実際にPythonでウェブスクレイピングする際の注意点について、見ていきましょう。
Pythonでウェブスクレイピングする際の注意点
お困り女子ウェブスクレイピングをする際に気をつけることはあるんですか?
なべくん規約や法令を守って、相手に迷惑をかけない配慮が必要です。
Pythonに限らず、ウェブスクレイピングは効率的なデータ収集の観点から大変有用なツールであることは間違いありません。しかし、法的・倫理的なリスクを回避し、安全に活用できる知識を身につけることが何よりも重要です。
- robot.txtに準拠する
- 利用規約に違反しない
- 相手サーバーに負荷をかけすぎない
- 著作権・個人情報保護を遵守する
私は過去に、正しい知識を持たずにスクレイピングを行ってトラブルになった例を多く見てきました。
この章では、安全なスクレイピング実践のために理解すべきrobots.txtの遵守、ウェブサイト利用規約の理解、サーバー負荷軽減のためのアクセス間隔調整、著作権・個人情報保護の法的側面、そしてアクセスブロックを回避するための具体的な策について解説します。
これらの注意点を実践すれば、あなたは安心してデータ収集を進められるでしょう。
注意点1. robots.txtに準拠する
robots.txtは、ウェブサイトの所有者が検索エンジンのクローラーやスクレイピングボットに対して、どのページへのアクセスを許可し、どのページへのアクセスを拒否するかを明示的に伝えるファイルのことで、世界中のウェブサイトのうち、少なくとも50%以上のウェブサイトがこのrobots.txtファイルを設定しているとされています。
robots.txtは、いわゆる紳士協定(厳密な強制力はない)であるため、直ちに違法とはなりませんが、運営者との予期せぬトラブルにつながる可能性があるので注意が必要です。
具体的なrobots.txtの記述例については、以下に掲載します。
# すべてのロボットに対して、すべてのコンテンツへのアクセスを許可します。
User-agent: *
Disallow: たとえば、ある企業の製品情報を収集したい場合、そのサイトのrobots.txtにDisallow: /product_data/という記述があれば、そのパス配下にある情報の自動収集は避けるべきだと判断できます。
お悩み女子robots.txtってどうやって見つけたらいいんですか?
なべくんほとんどのサイトではURLの最後に/robots.txtをつけ加えると確認できるますよ。
robots.txtに記載されたルールを遵守することで、あなたはウェブサイト運営者の意図を尊重し、信頼関係を損なうことなくデータ収集を行うことができます。
注意点2. ウェブサイト利用規約を違反しない
ウェブサイト利用規約とは、そのサイトの閲覧者や利用者に対して、サービスの利用条件や禁止事項を具体的に定めた規約のことで、以下のようにスクレイピング行為に関する明確な記載がされていることがあります。
禁止されている行為
TargetingIdeaService や TrafficEstimatorService のスクレイピング
TargetingIdeaService(TIS)と TrafficEstimatorService(TES)は、広告主や広告代理店がプログラムによってキーワードを生成し、Google 広告のキーワードおよび入札単価戦略を最適化するのに役立ちます。TIS または TES からのデータを、Google 広告のキャンペーンの作成と管理以外の目的で収集することは禁止されています。広告代理店または独立 Google 広告開発者の方が、外部 API ツールを通してクライアント(利用者)に TIS または TES のデータを提供する場合、最低限必要な機能(キャンペーンの作成、管理、レポート)をすべて満たしている必要があります。
Google 検索のスクレイピング、スクレイピングによるデータの購入
Google 検索結果ページやその他の Google のプロパティをスクレイピングすることはできません。また、スクレイピングされた Google のデータをサードパーティから間接的に入手することも、禁止されています。Google 以外の正当なデータソースから入手した検索データを含むレポートを公開する場合、データソースとデータ収集手法をレポートで開示する必要があります。
引用:Google広告ポリシー
日本の有名ニュースサイトやSNSプラットフォームの多くは、利用規約で自動データ収集、特にスクレイピングを明確に禁止しています。ただし、情報取得用のAPIを公開していることがほとんど。
過去には、無許可のスクレイピング行為が「不正競争防止法」や「業務妨害」にあたると判断され、数千万円から数億円規模の損害賠償を命じられた実際の事例もあります。
参考:保育園の口コミ、無断転用 スクレイピングしAIで改変
お悩み女子もし規約違反をしてしまったら、具体的にどんなリスクがあるんですか?
なべくん法的措置だけでなく、サービスの停止や社会的信用の失墜につながる可能性もあります
利用規約の内容を理解し、その内容に違反しないよう細心の注意を払うことは、安心・安全にスクレイピングを活用するための最低限の条件です。
注意点3. 相手サーバーに負荷をかけすぎない
昨今のレンタルサーバーは高性能なサーバーが多く、ある程度のアクセス集中状態にあっても耐えられるスペックを有していますが、格安サーバーや古くからのサーバー業者の場合、サーバーがダウンすることもあります。
サーバーがダウンしてしまうとサイト運営者だけでなく、サーバー運営会社にも多大な迷惑をかける可能性があり、訴訟問題に発展するケースも少なくありません。
参考:weev(wiki)
お悩み女子負荷をかけすぎない頻度ってどれくらいを想定すればいいの?
なべくん10回/分が一般的です。
推奨されるアクセス頻度は、一般的に1分あたり10回程度、つまり6秒に1回以上の間隔を空けることです。
ただし、APIによるアクセスの場合は、1回/秒とされていることがほとんど。
スクレイピングをする際は、相手サーバーに過度な負荷がかからないよう適切な遅延(タイムアウト)設定を組み込むことで、相手側に過度な負担をかけずに、安定したデータ収集を実施できます。
注意点4. 著作権・個人情報保護を遵守する
著作権は、文章、画像、動画などのコンテンツを作成したクリエイターに与えられる権利で、他者が無断で複製・利用することを禁じています。
参考:文化庁
一方、個人情報保護は、氏名、住所、連絡先など、個人を特定できる情報の収集、利用、管理に関する厳格なルールを定めています。
参考:個人情報保護法等
日本国内においては、著作権法第21条に定められた複製権があり、許可なくウェブコンテンツをスクレイピングすることはこれに抵触する場合があり、個人情報保護法においても企業の公開されている個人情報であっても、目的外利用や不適切な開示を厳しく制限しています。
例えば、公開されている個人の氏名と所属企業名をスクレイピングし、これらを許可なく第三者に提供する行為は法律に抵触する恐れがあるため、収集したデータが著作権の対象となるか、あるいは個人情報を含んでいないか、意図しない個人情報なども含まれていないかを確認し、利用目的を明確にした上で、関連する法的制約を遵守することが非常に重要です。
アクセスブロック 回避策
アクセスブロックとは、ウェブサイト側が、短期間に大量のアクセスを行ったり、不審な挙動を示したりする特定のIPアドレスからの接続を一時的、あるいは恒久的に遮断するセキュリティ対策です。
これは、ウェブサイトの安定稼働と悪意のある攻撃からの保護を目的としています。
同じIPアドレスから集中してリクエストが送られると、ウェブサイトはDDoS攻撃など不正なアクセスと判断し、数分から数時間のIPブロックを実施することがよくあります。
場合によっては、あなたのIPアドレスが数日から数週間にわたりブロックされ、目的のサイトにアクセスできなくなる事態に陥ることもあります。
このような事態を避けるには、以下の策を講じるのが効果的です。
| 回避策 | 説明 | メリット | デメリット |
|---|---|---|---|
| User-Agentを偽装 | スクレイピングツールのデフォルトのUser-Agentではなく、一般的なWebブラウザのUser-Agentを設定します。 | 不審なボットと判断されにくい | それだけでは完全な回避にならない |
| プロキシサーバーの利用 | 複数のプロキシサーバーを介してアクセスし、IPアドレスを分散させます。 | IPブロックのリスクを大幅に軽減する | 高品質なプロキシは費用がかかる、設定が複雑 |
| ランダムな遅延 | 各リクエスト間にランダムな秒数(例: 2秒から5秒)の遅延を設けます。 | 自然なアクセスパターンに見える | データ収集に時間がかかる |
| CAPTCHA対応 | CAPTCHAが表示された場合に、解決するロジックを実装するか、専用のサービスを利用します。 | 動的なサイトからのデータ収集を可能にする | 実装が複雑、費用がかかる場合がある |
お悩み女子もしIPアドレスをブロックされたら、どうしたらいいですか?
なべくんプロキシサーバーやVPNを使うのが効果的です
これらの倫理的かつ技術的な回避策を講じることで、あなたはデータ収集の継続性を確保し、ビジネスの中断リスクを最小限に抑えられます。
実践Pythonでウェブスクレイピング 具体的なデータ収集手法
お悩み女子実際にスクレイピングする手順やどこをチェックすればいいの?
なべくんスクレイピングが可能なサイトで検証してみましょう。
- サイト名:Zenn
- サイトURL:https://zenn.dev/
- 利用規約:https://zenn.dev/terms
- robots.txt:https://zenn.dev/robots.txt
上記のサンプルサイトを使わせていただき、実際にスクレイピングをする手順を考察していきます。
- robots.txt・利用規約を確認する
- 取得する要素を確認する
- スクリプトを書き、検証する
各スクレイピング手順について、それぞれ見ていきましょう。
手順1. robots.txt・利用規約を確認する
まずは、スクレイピングが可能かどうか利用規約とrobots.txtを確認します。
- [✓] robots.txtを遵守する
- https://zenn.dev/search から始まる検索結果ページにはアクセスしない。
- [✓] サーバーへの負荷をかけない
- リクエストの間には、最低でも1秒以上の十分な待機時間(sleep処理)を設ける。(第4条)
- [✓] 収集したデータを公開・再配布しない
- 収集したコンテンツは、個人の学習・分析目的でのみ利用する。コピーして自分のサイトに掲載したり、他人に渡したりしない。(第6条)
- [✓] 有料コンテンツは対象にしない
- 支払いをしていない有料コンテンツにアクセスを試みない。(第4条)
- [✓] 個人情報の扱いに注意する
- ユーザープロフィールなどを収集する場合、その情報を本人の許可なく公開するなど、プライバシーを侵害するような利用は避ける。(第4条)
User-agent: *
Disallow: /search
User-agent: Bingbot
Disallow: /search
User-agent: Yahoo Pipes 1.0
Disallow: /
User-agent: 008
Disallow: /
User-agent: voltron
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Livelapbot
Disallow: /
User-agent: Megalodon
Disallow: /
User-agent: ia_archiver
Disallow: /
Sitemap: https://zenn.dev/sitemaps/_index.xml以上のrobots.txtと利用規約から以下のことが読み取れます。
- /searchはスクレイピング禁止
- 特定のuser-agentを使用しない
- 利用規約を遵守する
- 有料記事を不正に入手しない
- 収集したデータを無断で転載・再配布しない
ごくごく当たり前といえば当たり前ですが、相手側に迷惑がかからないように紳士的にスクレイピングしましょう。
手順2. 取得する要素を確認する
スクレイピングが可能な範囲を確認できたところで実際にスクレイピングで取得する要素について確認していきましょう。
今回はPythonでスクレイピングするということなので、ZennのサイトからPythonに関する記事と最新の記事一覧を取得します。
- Pythonの記事一覧(タイトルと投稿者)
- 新着記事一覧(タイトルと投稿者といいね数)
要素を選択する手順は以下を参照してください。
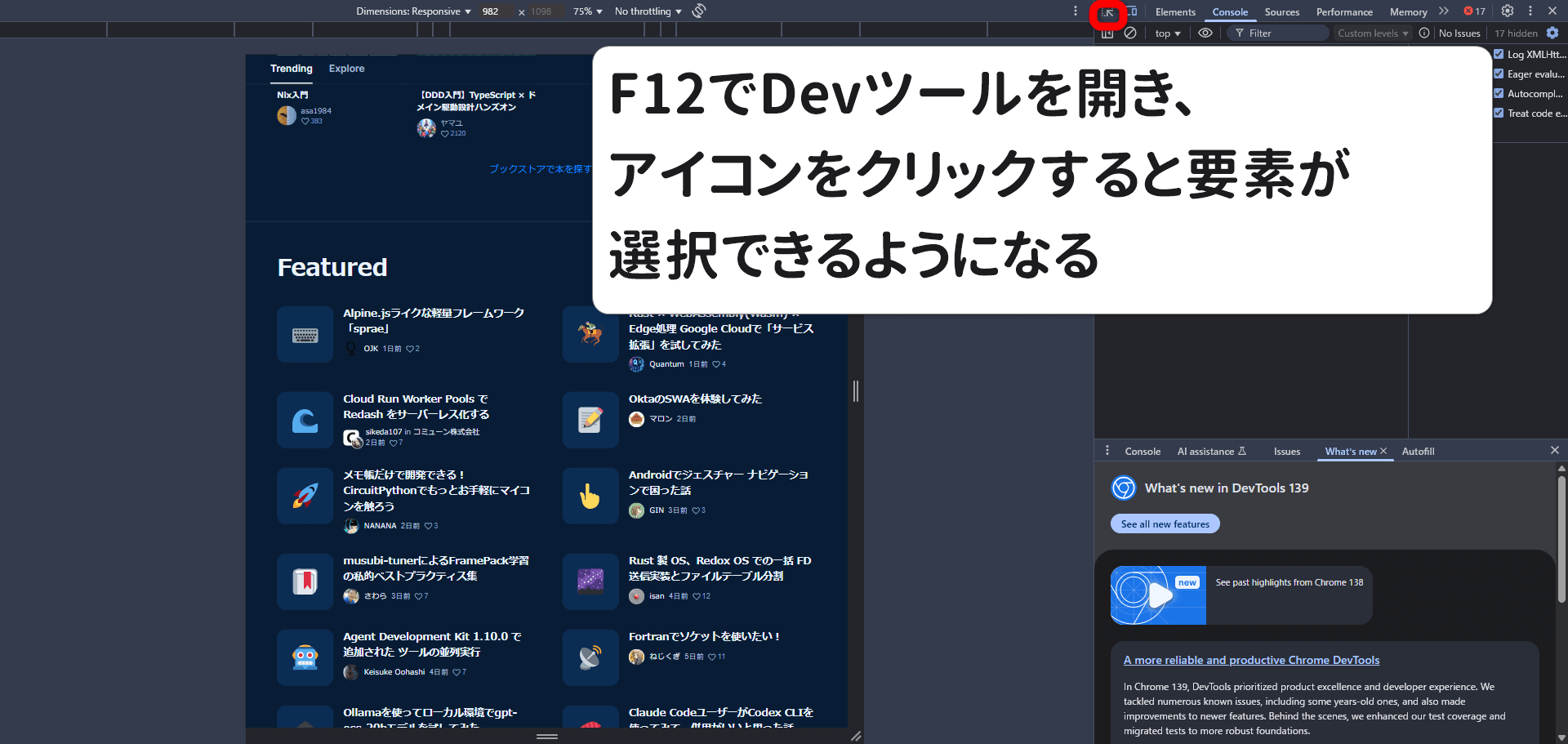
F12を押し、開発者ツールを開き、取得する要素を確認します。(マウスを右クリック→検証を選択でも同じ)
Devツール側左上の矢印アイコンをクリックし、要素を選択可能にする。(クリックすると微妙に色が変わります)
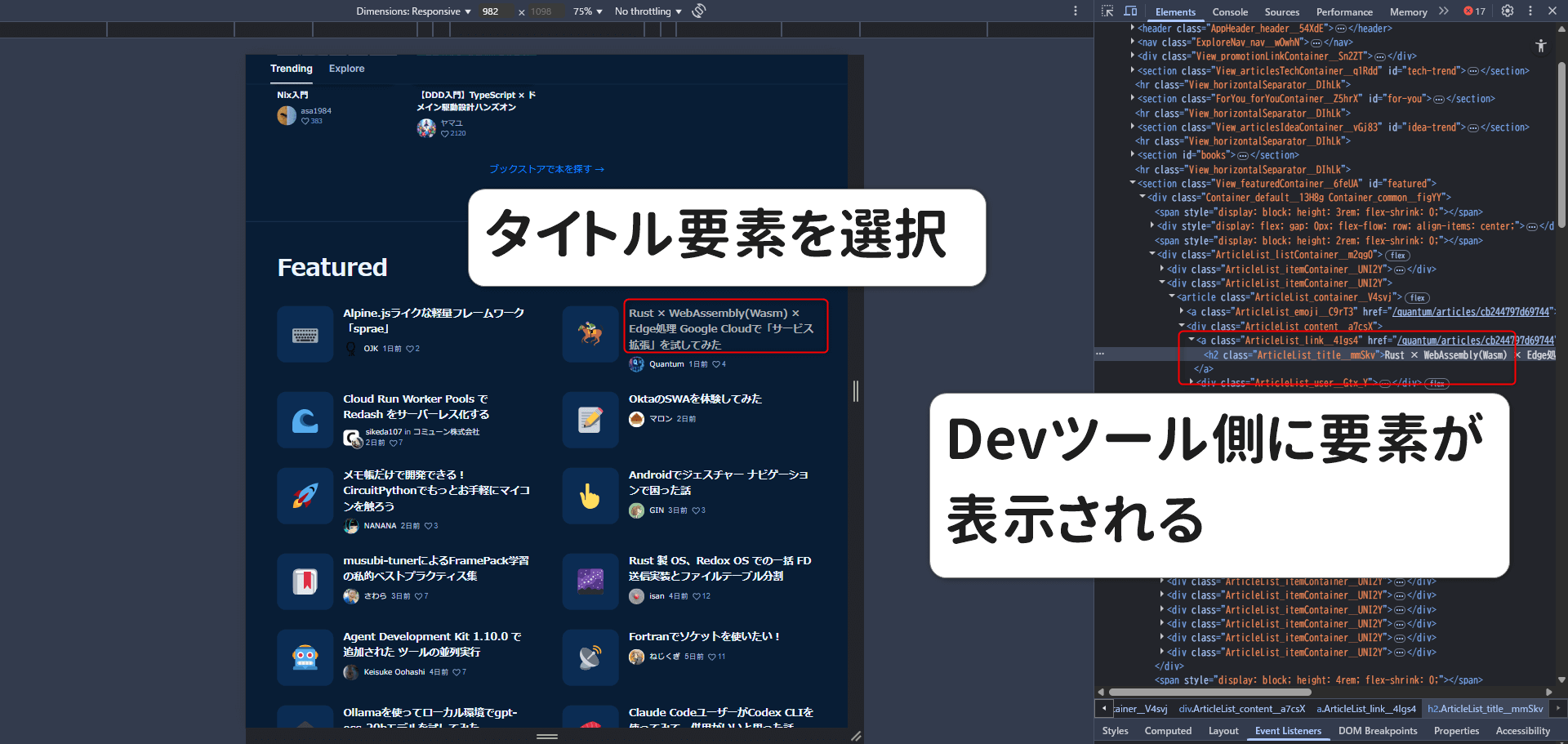
任意の要素を選択するとDevツール側のエレメントが切り替わる。(consoleやsourceになっている場合は、elementにタブを切り替えてください)
取得する要素を選択したら、マウスの右クリックで確定、Devツール側で再度右クリック→copy→copy selectorをクリックするとクリップボードに要素がコピーされるので、テキストエディターなどにペーストして使用する。
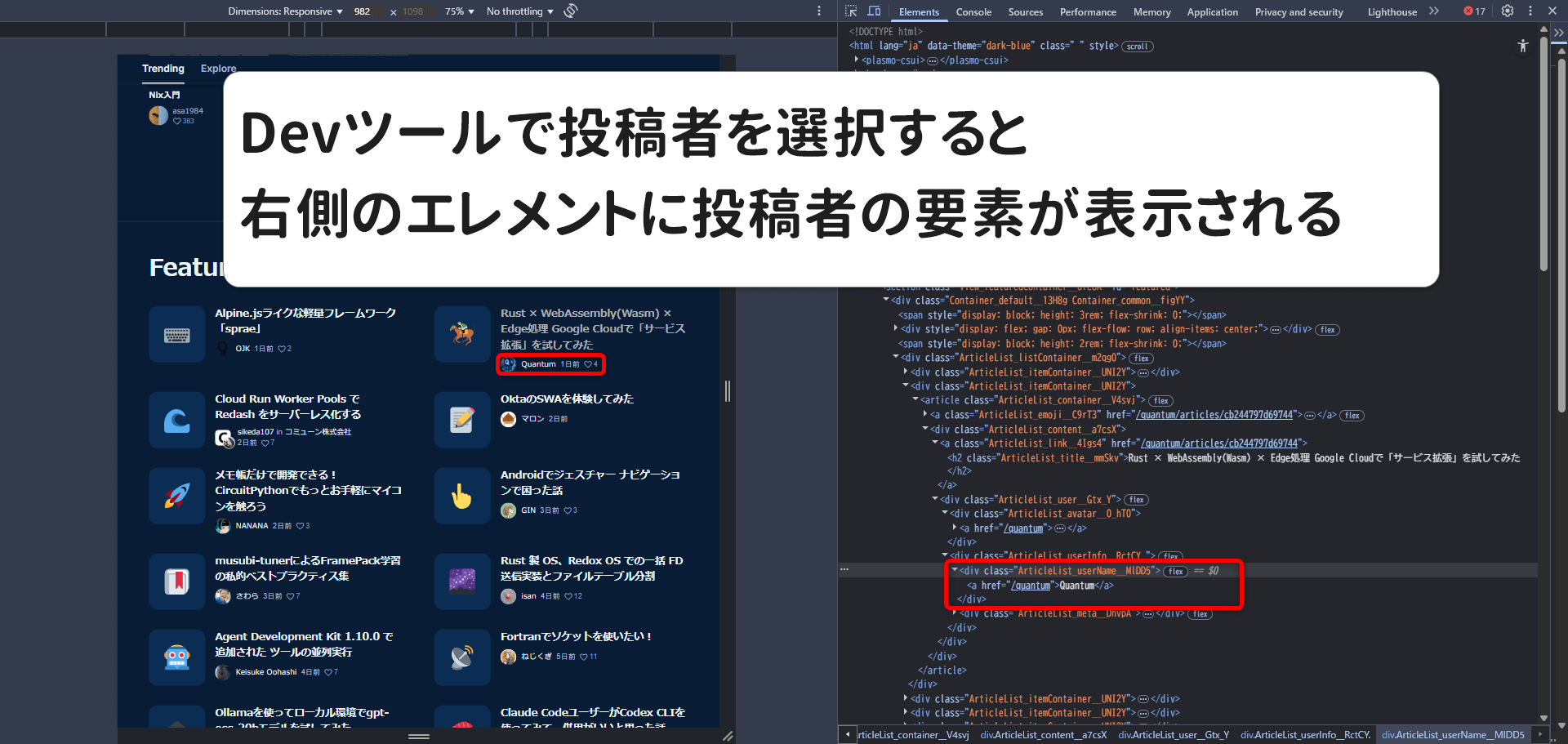
同様にDevツールで投稿者にカーソルをあて左クリックすると選択要素に表示が切り替わるので、右クリック→Devツール側で再度右クリック→copy→copy selectorをクリックして要素をコピーする
今回はCSSセレクターを選択して要素をコピーしてきましたが、複雑な構造をしているサイトの場合、CSSセレクターだけではうまくスクレイピング対象を捕捉できないこともあるため、必要に応じてXpathの要素を使い分けるようにするのがおすすめです。
スクレイピングでの使い分け
- IDやクラス名が適切に付与されているサイトではCSSセレクタを使う
- HTMLの構造が非常に複雑で、単純な親子関係では指定が難しいはXpathを使う
BS+Requestの組み合わせのときはCSSセレクタできれいに取得できるが、seleniumを使用しているときはXpathのほうがきれいに取得できることもあるので、時と場合によって使い分けられるようにするのがベター。
手順3. Pythonスクリプトを書き、検証する
今回は、ウェブスクレイピングをすることが目的であるため、開発環境に関しては言及しません。したがって、誰でもほぼ同じ動作環境が再現できるGoogle Colaboratory(通称:Colab)でコードの実装を行います。
まずは、zennからPythonの記事を取得するコードは下記の通り。
- URL:https://zenn.dev/topics/python
- タイトル要素:ArticleList_title__mmSkv
- 投稿者要素:ArticleList_userName__MlDD5
# 必要なライブラリをインポート
import requests
from bs4 import BeautifulSoup
import time # サーバーへの配慮のためのライブラリ
# 対象のURL
url = 'https://zenn.dev/topics/python'
# --- ここからスクレイピング処理 ---
try:
# サイトにアクセスしてHTMLを取得
# ヘッダーを付けてボットではないように見せかける(推奨)
# User-Agentを指定することで、サーバーからアクセスを拒否されにくくなります。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
# ステータスコードが200番台でない場合(エラーの場合)に例外を発生させます。
response.raise_for_status()
# BeautifulSoupでHTMLを解析
# 'html.parser'はPythonの標準ライブラリで動作するパーサーです。
soup = BeautifulSoup(response.text, 'html.parser')
# 各記事は <article> タグで囲まれており、特定のクラス名を持っています。
# このクラス名を持つarticle要素をすべてリストとして取得します。
articles = soup.select('article.ArticleList_container__V4svj')
print(f"--- {url} からの記事情報 ---")
print(f"{len(articles)} 件の記事が見つかりました。\n")
# 取得した各記事をループして、必要な情報を抜き出す
# enumerate を使うと、インデックス番号と要素を同時に取得できます。
for i, article in enumerate(articles):
# 記事タイトルを取得 (h2タグ、クラス名が 'ArticleList_title__mmSkv' を持つ要素)
title_element = article.select_one('h2.ArticleList_title__mmSkv')
# 要素が見つかった場合のみテキストを取得し、見つからない場合は「タイトル不明」とする
title = title_element.text.strip() if title_element else "タイトル不明"
# 投稿ユーザー名を取得 (divタグ、クラス名が 'ArticleList_userName__MlDD5' を持つ要素)
user_element = article.select_one('div.ArticleList_userName__MlDD5')
# 要素が見つかった場合のみテキストを取得し、見つからない場合は「ユーザー名不明」とする
user_name = user_element.text.strip() if user_element else "ユーザー名不明"
# 取得した情報を整形して表示
print(f"[{i+1}]")
print(f" タイトル: {title}")
print(f" ユーザー名: {user_name}\n")
# --- エラー処理 ---
# 通信関連のエラーが発生した場合の処理
except requests.exceptions.RequestException as e:
print(f"HTTPリクエスト中にエラーが発生しました: {e}")
# その他の予期せぬエラーが発生した場合の処理
except Exception as e:
print(f"処理中にエラーが発生しました: {e}")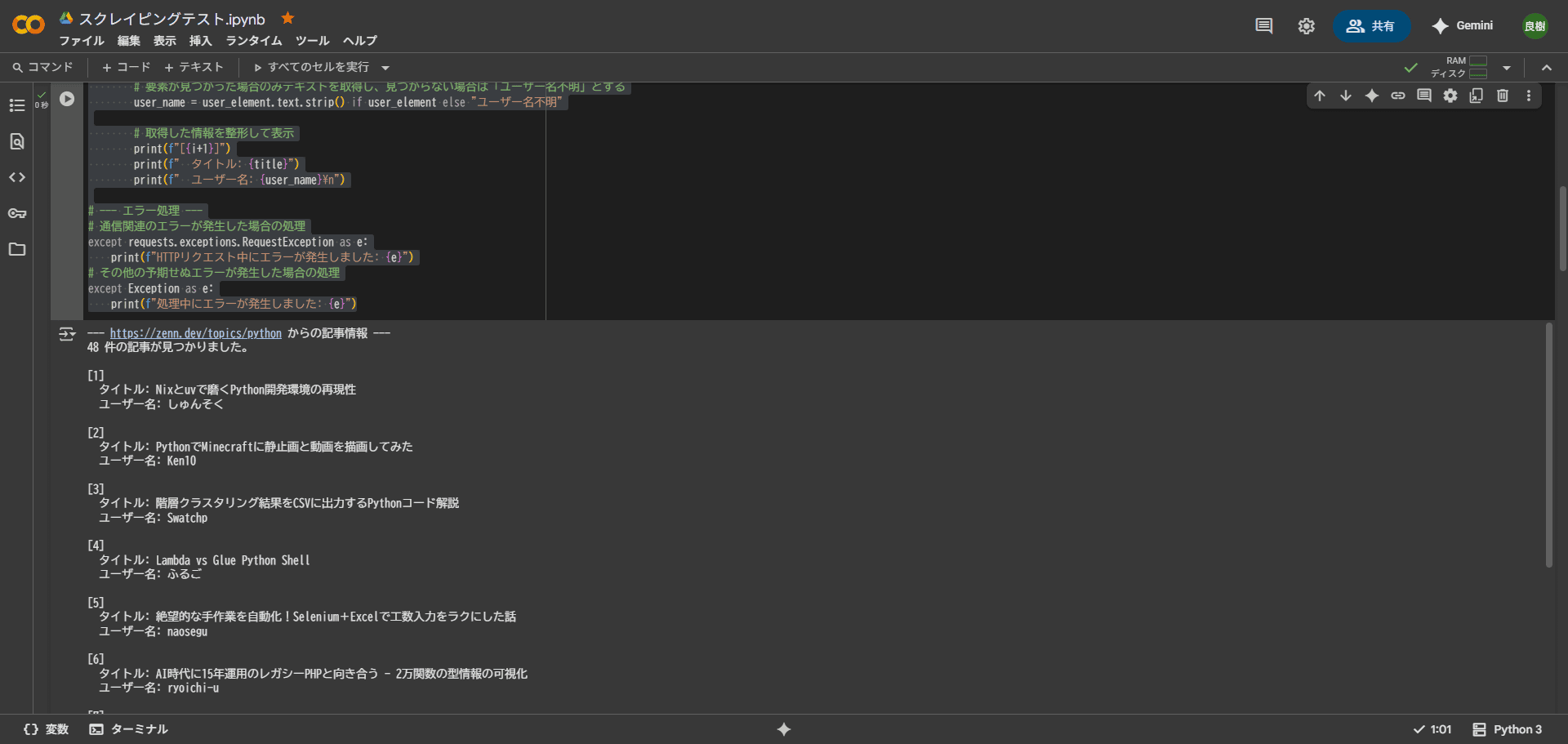
各処理の内容についてはコメントアウトしていますが、スクレイピング処理を行う際に注意すべきなのが例外処理を実装し忘れてしまうこと。
例えば、上記のコードで取得したい要素がなかった場合、例外処理を実装していないとコードがそこで止まってしまいエラーになってしまいます。つまり取得したい要素を固めたタイミングでその要素がなかったときのこともワンセットで考えておくと手戻りもなくスムーズに実装を進められます。
なべくん実際にコードを実行していくと例外処理の重要さが身にしてわかりますよ。
参考までに以下のリンクにGoogle Colabのサンプルコードを置いておくので参考にしてください。
参考:Google Colab
ウェブスクレイピングをする際によくある質問(FAQ)
Pythonでウェブスクレイピングする目的を明確にし、セキュリティと倫理観をもった活用を
お悩み女子スクレイピングって効率化が期待できる反面、やっぱり不安を感じます。
なべくん安心してデータを活用するためには、安全で倫理的なシステム構築が最も大切です。
これまでにPythonでスクレイピングする方法について解説してきましたが特に強調したいことは、Pythonウェブスクレイピングは強力なツールであるからこそ、セキュリティと倫理観をもった活用が不可欠です。
国内での事例はそう多くありませんが、利用規約に違反するスクレイピングは、サイトへのアクセスブロックはもちろんのこと、最悪の場合、損害賠償請求に発展する可能性も十分に考えられます。
| 確認事項 | 具体的な行動 | 留意点 |
|---|---|---|
| robots.txtの確認 | ウェブサイトURLの末尾に/robots.txtを追加し、許可範囲を把握 | 許可されている範囲内でスクレイピングを実行 |
| 利用規約の熟読 | ウェブサイトのサービス利用規約を確認し、スクレイピングの禁止事項を把握 | 違反した場合、法的措置やアクセスブロックのリスクがある |
| サーバー負荷への配慮 | リクエスト間に適切な待機時間を設定する | ウェブサイトに過度な負荷をかけず、IPアドレスブロックを避ける |
| 著作権・個人情報保護意識 | 収集データに著作権侵害や個人情報保護に抵触する内容がないか確認 | 無断公開や不適切な利用は法的な問題を引き起こす可能性が高い |
ウェブスクレイピングをする際は、相手側のサーバーに負荷をかけていることを念頭に置き、上記の各方面への配慮を忘れずに実施し、強力なツールを安心・安全に運用しましょう。







